Abstract
[English]: This study aims to examine and compare students’ level of statistical thinking with different cognitive styles (Field-dependent, FD and Field-independent, FI) in solving mathematical problems. It is descriptive qualitative research involving 31 ninth-graders given the Group Embedded Figure Test (GEFT) to determine their cognitive styles. From the results of GEFT, four students with two cognitive styles and high mathematics ability were selected as participants. A test and interviews were administered for data collection. The test was analyzed based on the level of statistical thinking indicators, and the interview results were used to confirm and explore the students' statistical thinking. The results of data analysis revealed that in representing data, both FI and FD students are at transitional level. In other stages of statistical thinking: describing data display, organizing and reducing data, analyzing and interpreting data, FD students reach a quantitative level meanwhile FI students are at an analytical level. Indeed, students with FI cognitive style have a higher level of statistical thinking than FD students. This finding shows that characteristics of students with FI, for example, being more analytic, support the achievement of better levels of statistical thinking.
[Bahasa]: Penelitian ini bertujuan untuk mengidentifikasi dan membandingkan level berpikir statistik siswa dengan gaya kognitif berbeda (Field-dependent, FD dan Field-independent, FI) dalam memecahkan masalah matematika. Penelitian ini merupakan penelitian kualitatif deskriptif yang melibatkan 31 siswa kelas 9. Siswa tersebut diberikan Group Embedded Figure Test (GEFT) untuk menentukan gaya kognitif. Selanjutnya, dipilih 4 siswa pada kedua gaya kognitif dengan kemampuan matematika tinggi. Data dikumpulkan melalui tes dan wawancara. Hasil tes dianalisis berdasarkan indikator level berpikir statistik dan hasil wawancara dianalisis untuk mengonfirmasi dan menggali lebih dalam berpikir statistik siswa. Hasil analisis data menunjukkan bahwa dalam menyajikan data, siswa FD dan FI berada pada level transisional. Pada tiga tahap berpikir statistik lain; menjelaskan sajian data, mengatur dan mengurangi data, menganalisis dan menerjemahkan data, siswa FD berada pada level kuantitatif sedangkan siswa FI berada pada level analitik. Dalam hal ini, siswa dengan gaya kognitif FI memiliki level berpikir statistik yang lebih tinggi dibandingkan dengan siswa FD. Hasil penelitian ini menunjukkan bahwa karakteristik siswa dengan gaya kognitif FI, misalnya cenderung lebih analitis dibandingkan FD, mendukung capaian level berpikir statistik yang lebih baik.
Downloads
Introduction
Statistical thinking is the ability to describe, organize, present, analyze and interpret data and apply understanding of statistical concepts in everyday life by providing criticism, evaluation, and making generalizations (Gal, 2002). If the ability to think statistically is high, then an understanding of the definition of statistical objects and attention to statistics is also good (Aizikovitsh-Udi et al., 2016). Statistical thinking can develop students’ critical thinking, especially on how they receive information, manage the correctness of the information, and provide comments (Aizikovitsh-Udi, Kuntze, & Clark, 2016; Kuntze, Aizikovitsh-Udi, & Clarke, 2017; Lizarelli, Antony, & Toledo, 2020). Moreover, it relates to students' creativity in solving problems with various kinds of solutions (Akaike, 2010). It is also able to develop students' reasoning in decision making and help to build a basic understanding of statistical material (Garfield et al., 2015). In this case, understanding students' statistical thinking in general and examining stages of statistical thinking students have in specific are critical to inform instructional practices, especially problem-solving activities in mathematics classrooms, which can be continuously improved to support the development of the students' thinking (Marlissa & Widjajanti, 2015; Sopamena et al., 2018). The observation of the students’ statistical thinking process can be done by giving students a problem so that the cognitive processes that occur can be observed directly (Lailiyah et al., 2020).
Several studies were conducted to investigate students’ statistical thinking in solving mathematical problems. English and Watson (2015) studied the development of students' understanding of variation in measurement as a foundation for statistical thinking. It was found that using the designed lessons; many students can develop the meaning of variation. Garfield et al. (2015) reviewed relevant research on novice and expert thinking, including statistical thinking. They account for the importance of developing students’ reasoning about samples and sampling variability to support students’ statistical thinking. Some other studies focus on levels of statistical thinking. Jones et al. (2001) evaluated primary students’ levels of statistical thinking after providing some interventions. The results reveal that the vast majority of the students’ levels of statistical thinking are at level 2 (transitional level). Students exhibiting that level typically give incomplete responses when they interpret visual displays; their thinking is often characterized by naive and inflexible attempts to quantify and represent data. Groth (2003) examined fifteen high school students’ levels of thinking. The study found that the students have varied levels of thinking from a pre-structural to a relational level. Thus, it can be concluded that elementary school students are at a transitional level while high school students are very varied. In this case, the statistical thinking of secondary school students can also vary.
As far as our concern, those prior studies have not considered students’ cognitive styles in researching statistical thinking. Besides, considering the fact that the students are in a transition period from concrete thinking to abstract thinking (Patton & Santos, 2012), further research is needed to investigate their statistical thinking. In addition to their thinking period, cognitive styles relate to students’ mathematics performance (Pitta-Pantazi & Christou, 2009; Seo & Taherbhai, 2009; Tinajero & Páramo, 1998). The need to understand students' thinking in solving mathematical problems is an important part of mathematics education. Research that describes students' cognition in mathematics topics has the potential to improve instructional practices. Therefore, the current study aims to examine and compare students’ levels of statistical thinking who have different cognitive styles in solving mathematical problems.
Theoretical review
Statistical thinking
There are several theories on statistical thinking, including a four-dimensional framework for statistical thinking (Wild & Pfannkuch, 1999) and four stages of the statistical thinking process (Jones et al., 2000). Wild and Pfannkuch (1999) propose a four-dimensional framework describing the elements of statistical thinking during a data-based investigation. The first dimension (investigative cycle) has five stages; problem, plan, data, analysis, and conclusions. The second dimension (types of thinking) has five types; recognition of the need for data, transnumeration, consideration of variation, reasoning with statistical models, and integrating the statistical and contextual. The third dimension (interrogative cycle) has five stages; generate, seek, interpret, criticize, and judge. The last dimension (disposition) has eight elements; skepticism, imagination, curiosity and awareness, openness, a propensity to seel deeper meaning, logic, engagement, and perseverance.
Jones et al. (2000) differentiate four stages of statistical thinking. It consists of Describing Data Displays (D), Organizing and Reducing Data (O), Representing Data (R), and Analyzing and Interpreting Data (A), abbreviated as DORA. Describing data display is reading data directly on presenting data, finding information explicitly, recognizing graphic provisions, and making a direct relationship between data and its presentation. Organizing and reducing data is collecting, classifying, sorting, and summarizing data, which involves characterizing data such as using a central size and distributing data. Representing data is presenting data in a visual form so that it looks attractive. Analyzing and interpreting data involve recognizing patterns and trends in the data so that conclusions and data predictions can be drawn. This research follows Jones’ four stages of statistical thinking since it is less complicated than Wild and Pfannkuch's framework, which makes data collection and analysis more feasible.
There are also several levels of statistical thinking, including four levels of statistical thinking as postulated on the basis of the Structure of the Observed Learning Outcome (SOLO) model. The level of statistical thinking consists of level 1 (idiosyncratic), level 2 (transitional), level 3 (quantitative), and level 4 (analytical) (Jones et al., 2001). The idiosyncratic level is the ability to think structurally, which involves the student with things that are the focus of the problem but are disturbed or confused by irrelevant aspects. The transitional level is the ability to think unstructured (transition from idiosyncratic and quantitative thinking), where the attention is focused only on one aspect of the data and sometimes returns to the characteristics of the idiosyncratic level. The quantitative level is the ability to think quantitatively where the attention is focused on more than one aspect of data. Level 4 (analytical) is the ability to think analytically and quantitatively about data and being able to explain various perspectives based on the data obtained.
In this study, in order to attain a comprehensive picture of the students’ statistical thinking, we examined it in two dimensions; stages and levels of statistical thinking, as presented in Table 1. The first dimension differentiates four stages of statistical thinking. It describes the stages or flow of how a student thinks about solving statistical problems. Meanwhile, the second dimension covers four levels of statistical thinking as postulated on the basis of the Structure of the Observed Learning Outcome (SOLO) model. It explicates the achievement or the results of students’ ability to think about statistical problems.
Cognitive styles and problem-solving
Problem-solving involves students' thinking, which is affected by their cognitive styles. Cognitive style is a student's unique way of learning related to acceptance, processing, attitudes to information, and habits related to the learning environment (Marlissa & Widjajanti, 2015). Each student's cognitive style is different; therefore, learning must facilitate all types of student cognitive styles (Krisdiantoro & Prihatnani, 2019). Students' cognitive styles' differences are significantly correlated with problem-solving, students’ learning outcomes, and mathematics appreciation (Cataloglu & Ates, 2014; Klaczynski, 1994; Marlissa & Widjajanti, 2015; Tinajero & Páramo, 1998).
There are various kinds of cognitive styles: (1) field-dependent (FD) and field-independent (FI), (2) impulsive and reflexive, (3) sensory thinkers, intuitive thinker, sensory feelers, intuitive feelers, (4) visualizer and verbalizer (Hudson et al., 2006; Kilburg & Siegel, 1973; McIntyre & Capen, 1993; Toomey & Heo, 2019; Witkin et al., 1977). FI and FD are specifically important in education since they have widespread implications in learning and teaching (Mahvelati, 2020; Mulbar et al., 2017). FD/FI particular characteristics can significantly affect learners’ processing behavior in three information-processing stages: attention, encoding, and memory. FD/FI cognitive construct is described as two contrasting habits of information processing and is regarded as one possible explanation for differences in learning (Mahvelati, 2020).
FD and FI students have different characteristics in learning mathematics. FD students tend to be passive in processing information, do something as it is told, focus on the global aspect of the given information, have difficulties distinguishing concepts and structures in the relevant collection of information, and use a previously known method when solving problems (Mahvelati, 2020; Witkin et al., 1977). On the other hand, FI students have high analytical skills and good restructuring, are independent in the learning process, and can solve problems systematically and use a variety of strategies when solving problems (Good & Brophy, 1990). The results of this study are expected to provide insight into whether students with distinct cognitive styles have similar levels of statistical thinking or not.
Methods
This study follows a descriptive qualitative perspective, which involves interpretive and naturalistic approaches to describe processes and meanings (Denzin & Lincoln, 2005). It involved 31 ninth-grade students who were given Group Embedded Figure Test (GEFT) adopted from Witkin et al. (1977) to determine their cognitive styles. The instrument includes 25 complex figures that require students to recognize and identify a simple hidden shape in each set of complex figures. The students who can correctly find more hidden figures are found to be better at the process of separating a figure from a confusing background. They are classified as field-independent (FI) and vice versa for field-dependent (FD). The reason for choosing the ninth-grade students is because they have learned the measures of central tendency. The use of GEFT to determine students’ cognitive styles is due to its psychometric properties- a valid and reliable instrument for assessing one dimension of cognitive style (Mykytyn, 1989). The results of GEFT showed that 17 students are FD, and the remaining is FI. Afterward, we selected two students (four participants in total) from each cognitive style with high mathematical abilities. We assumed that the selected students would have higher stages and levels of statistical thinking in solving the given tasks, which are important for this study to have rich data.
Data was collected using a test and interviews to examine the students' statistical thinking. The test was adopted from Jones et al. (2000); five problems about data presentation and four problems relating to data centers. In solving the test, the students are expected to be: (1) able to read and interpret data in the form of line diagrams and pie charts, (2) able to determine the mean of single data, and (3) able to present, read, and interpret data in the form of a bar chart. These enable this research to examine students' stages and levels of statistical thinking, as shown in Table 1. The interviews were structured based on four stages of statistical thinking (D, O, R, A). It consisted of nine questions to dig up information on the first part of the given test and eight questions to explore the second part. Some samples of the questions are; Do the two diagrams show the same data? Why? Explain! (D), How do you determine the average number of laptops? (O), How do you complete the bar chart? (R), and What can you conclude from the data? (A). The test was initially validated by three experts (2 mathematics education lecturers who are experts in statistics and a mathematics teacher) resulted in an average score of 3.9 out of 5. Three validators had stated that the instrument was suitable to use with some revisions. The revisions included clarifying the line diagram to be readable, revising the data in the line diagram and the pie chart to be equal, and replacing some ambiguous question sentences.
The four participants were given the test then interviewed to confirm and explore their statistical thinking deeply in solving mathematical problems. Data sources triangulation was used to compare the results of one subject with another subject in the same cognitive style. The data was analyzed through data reduction, presentation, and conclusion drawing and verification (Miles & Huberman, 1994). In data reduction, each of the authors coded students’ answers and interview transcripts in a deductive way, referring to Table 1. The consistency of students’ statistical thinking was also examined using the data. Then, we analyzed the results of the coding to get a consensus. In data display, we organized, compressed assembly of students’ answers in a matrix. In conclusion drawing and verification, as the matrix fills up, preliminary conclusions are drawn and verified. Based on the matrix, we concluded each students' level of statistical thinking.
Findings and Discussion
This section presents each participant’s works on the test and the interviews, representing their stages and statistical thinking levels.
Field-dependent students’ stages and level of statistical thinking
Describing data displays (D)
Figure 1, Figure 2, and Table 2 show FD students' explanations of the data display. Overall, FD1 and FD2 wrote down all information contained in the two diagrams in problem 1. FD1 recognized the conditions in the diagrams and the same data with two different data presentations (FD1.2 and FD1.3). However, FD1 was not careful in reading the data, resulting in unreadable data. Meanwhile, FD2 stated that the two diagrams were the same data because the data goes up and down (FD2.3 and FD2.4). In problem 2, FD1 confidently shows her knowledge of the terms of the graph (FD1.5). Meanwhile, FD2 explained the data about the math scores of class IX MTsN Gresik (FD2.5). In this case, FD2 recognized the two data presentations were the same data with some adjustments in data presentation, but FD2 could not mention appropriate reasons.
Figure 1. The answers of FD1 in describing display of the data
Figure 2. The answers of FD2 in describing data display
| Stages of statistical thinking | Levels of statistical thinking | |||
|---|---|---|---|---|
| Idiosyncratic | Transitional | Quantitative Level | Analytical Level | |
| 1. Describing data displays (D) | 1. Describing unfocused data and irrelevant information, and there is no knowledge of the terms of the chart. | 1. Describing the data hesitantly and incompletely but showing some knowledge of the chart terms. | 1. Describing the data partially and confidently and demonstrate knowledge of chart terms. | 1. Describing data confidently and completely and demonstrate knowledge of chart terms. |
| 2. Unable to recognize when there are two different data presentations on the same data or able to show some recognitions but unable to give relevant reasoning. | 2. Able to recognize when there are two different data presentations on the same data but use reasoning based on provisions. | 2. Able to recognize when there are two different data presentations on the same data by making partial adjustments to the data in the presentation of the data. | 2. Able to recognize when there are two different data presentations on the same data by making appropriate adjustments between the data presented. | |
| 3. Able to evaluate two different data presentations on the same data by considering irrelevant aspects. | 3. Able to evaluate two different data presentations on the same data by focusing on only one aspect. | 3. Able to evaluate two different data presentations on the same data by focusing on more than one aspect but not explaining the relationship between aspects. | 3. Able to evaluate two different data presentations on the same data by explaining the relationship between aspects and can be understood. | |
| 2. Organizing and reducing data (O) | 1. Unable to group or sort data or provide irrelevant groupings. | 1. Grouping or sorting data inconsistently or grouping data using unexplained criteria. | 1. Able to group or sort data and able to explain the basis for grouping data. | 1. Grouping or sorting data using several ways and able to explain the basis for grouping data. |
| 2. Unable to recognize when information is lost in the reduction process. | 2. Able to recognize when data reduction occurs but providing an unclear or irrelevant explanation. | 2. Able to recognize when data reduction occurs and able to explain the reasons for the reduction. | 2. Able to recognize that data reductions can occur in different ways and provide full explanations for the different reductions. | |
| 3. Unable to describe the data in terms of representation or "in particular." | 3. Describing the data doubtfully and incompletely in terms of representation or "in particular." | 3. Able to give an exact measure "specifically" which is close to one of the centers (mode, median, mean), but the reasoning is incomplete. | 3. Describing "specifically" about the data in terms of data measures at the center, such as the median or mean. | |
| 4. Unable to describe the distribution of data and provide irrelevant responses | 4. Able to find inappropriate measures in an attempt to make data dissemination acceptable. | 4. Able to use the size obtained or the results of the exact description, but the explanation is not complete. | 4. Able to use the range or measure of data obtained and have the same meaning as the range. | |
| 3. Representing data (R) | 1. Making inappropriate data representations when asked to complete partially drawn graphs related to a given set of data. | 1. Making the appropriate presentation of the data in several aspects when asked to complete a partially drawn graph related to a given data set. | 1. Making appropriate data presentation when asked to complete a partially drawn graph of a given data set may experience some difficulties, such as using a scale. | 1. Making appropriate data representations when asked to complete partially constructed charts related to a given data set, working as effectively as using a scale. |
| 2. Producing an inaccurate presentation of data that does not explain the rearrangement of a series of data. | 2. Able to produce data presentation with partial accuracy but unable to rearrange the data. | 2. Producing an appropriate data presentation, which shows several attempts to reorganize the data. | 2. Able to produce many precise representations of the data, some of which reorganizes the data. | |
| 4. Analyzing and interpreting data (A) | 1. Unable to make a response or give inaccurate or irrelevant responses to the question, "what information is contained in the presentation of the data?". | 1. Able to make a relevant but incomplete response to the question, "what information is contained in the data display." | 1. Able to make relevant responses to the question, "what information is contained in the data display." | 1. Able to make an understandable contextual response to the question, "what information is contained in the presentation of the data". |
| 2. Responding or giving inaccurate or incomplete responses when asked to "read data." | 2. Able to give appropriate responses to several aspects related to "reading data" but unable to make comparisons. | 2. Able to provide multiple appropriate responses when asked to "read data" and make some global comparisons. | 2. Able to provide multiple appropriate responses when asked to "read the data" and make related and understandable comparisons. | |
| 3. Unable to respond or give inappropriate or incomplete responses when asked to "make conclusions about the data." | 3. Giving unclear responses or inconsistent responses when asked to "conclude the data." | 3. Able to use the data and understand the situation when asked to "make conclusions about the data" with incomplete reasons. | 3. Able to provide several appropriate responses when asked to "make conclusions about the data." | |
| FD1 transcript | FD2 transcript |
|---|---|
| R : Do the two diagrams show the same data? | R : Do the two diagrams show the same data? |
| FD1.2 : Hmmm .. I think they are same. | FD2.3 : Yes, I think the same. |
| R : Can you explain the reason? | R : Why is it the same? |
| FD1.3 : Because both pictures show laptop sales data in 1 year (pointing to the title of the image). | FD2.4 : Because the sales data goes up and down hehe .. |
| R : What is known from the data? | R : Show me which one is up? |
| FD1.5 : From these data, I can find out the math tests of grade IX students at MTsN Gresik. | FD2.5 : This one (pointing to the diagram in Figure 1), 5% to 11.25% (pointing to the diagram in Figure 2). |
Thus, FD1 and FD2 could recognize that the two different data presentations were the same data with partial adjustments to the data presented, but they were unable to provide precise reasons. FD1 and FD2 evaluated the two different data presentations on the same data by focusing on more than one aspect, but they did not explain the relationship among aspects. Therefore, it can be concluded that statistical thinking of FD1 and FD2 in describing the data display is at level 3 (quantitative).
Organizing and reducing data (O)
The answers of FD students in organizing and reducing data are confirmed by the interview transcript in Table 3.
| FD1 transcript | FD2 transcript |
|---|---|
| R : Then, how do you determine the average laptop sold? | R : What formula do you use to determine the average sold laptop? |
| FD1.7 : 160: 12 | FD2.7 : Hehe… I don’t know. Anyway, all of them are divided by 12. |
| R : Where do you get 160 and 12? | R : How was the result? |
| FD1.8 : 160 is the number in the diagram and 12 from the number of months | FD2.9 : 160: 12 = about 13 ft |
| R : How do you determine the average math test grade IX? | R : How do you determine the average math test grade IX? |
| FD1.9 : 277: 40 | FD2.11 : The same as before... these are all added up and then divided by this amount (while showing the problem) |
| R : 277 and 40; where do the numbers come from? | R : How many are the total? |
| FD1.10 : 277 is the sum of all the numbers, and 40 is the total amount of the number | FD2.12 : 277: 40 = about 6 or more (while remembering the results of the count) |
In determining the average sales of laptops for one year in problem 1, FD1 used the division by the number of months in that one year (12 months) (FD1.7 and FD1.8). In determining the average mathematics score for problem 2, FD1 used division by the number of students in the class (40 students) (FD1.9 and FD1.10). In determining the average sales of laptops for one year at problem 1, FD2 immediately wrote down the answer 13 (FD2.7 and FD2.9). However, in the interview, FD2 explained that 13 came from the number of laptops sold divided by the number of months in one year. In determining the average value of mathematics at problem 2, FD2 wrote the answer around 6 (FD2.11 and FD2.12). In this case, FD1 and FD2 were able to group, explain the basis for grouping data appropriately, recognize when data reduction occurs, explain the reasons for the reduction, and determine the average data (mean). However, the reasons given are irrelevant or incomplete. It can be concluded that FD1 and FD2 reached the quantitative level of statistical thinking in organizing and reducing data.
Representing data (R)
Figure 3 and Figure 4 are FD students’ answers in representing data. This is confirmed by the excerpts of the interview in Table 4.
| FD1 transcript | FD2 transcript |
|---|---|
| R : What form are you presenting? | R : What data presentation did you make? |
| FD1.11 : Bar chart ... but previously, I was confused. | FD2.14 : Bar chart |
| R : Why are you confused? | R : Did you experience difficulties or not? |
| FD1.12 : I am confused about the diagram questions. | FD2.15 : Emmm..a little confused with the picture in the question .. but in the end, I answered as well as I did. |
| R : How do you complete the diagram? | R : How do you complete the diagram? |
| FD1.13 : Value 4 to 6, value 5 to 5, value 6 to 6, value 7 to 10, value 9 to 8, value 10 to 6 | FD2.16 : Value 4 to 6, value 5 to 5, value 6 to 6, value 7 to 10, value 9 to 9, value 10 to 5 (while looking at the diagram made). |
| R : Which do you think is the value of the 4 in the diagram? | R : Are you sure the score of 9 is 9? |
| FD1.14 : The shape of the bars is between 4 and 5 (pointing at the answer). | FD2.17 : (counting again on the problem) ... hehe… there are 8. |
Figure 3. The answers of FD1 in representing data
Figure 4. The answers of FD2 in representing data
In Figure 3, FD1 was able to make data presentations appropriately when asked to complete a partially drawn graph (FD1.11 and FD1.13). FD1 also continued her drawing using scale appropriately. FD1 was also able to produce correct data presentation; some of the data were rearranged to look neat. In Figure 4, FD2 was initially confused when presenting the data, although it was finally answered (FD2.14 and FD2.16). FD2 assumed that the diagram in the answer sheet was the same as question number 1. FD2 read the data by paying attention to the Cartesian coordinates and rearranged the data. FD1 drew a line graph instead of a bar graph, as asked in the test, and FD 2 only drew the points in the cartesian diagram. FD1 and FD2 drew an appropriate presentation of the data in several aspects when asked to complete a partially drawn graph related to a given data set and produced data presentation with partial accuracy but unable to rearrange the data. It can be concluded that both FD students’ statistical thinking in representing data is at level 2 (transitional).
Analyzing and interpreting data (A)
The FD students' answers in representing data are confirmed by the interview transcript in Table 5.
| FD1 transcript | FD2 transcript |
|---|---|
| R : What can you conclude from the laptop sales data? | R : What conclusions do you take from the laptop sales data? |
| FD1.15 : From the data above, it is not always profitable that there is a loss when selling. | FD2.18 : According to my conclusion from the data, there are sales prices going up and down. |
| R : In what month did laptop sales have the highest increase? | R : In what month were the highest sales of laptops? |
| FD1.17 : August. (while looking at the diagram) | FD2.19 : August (while looking at the diagram) |
| R : If laptop sales were the highest in what month? | R : In what month did laptop sales have the highest increase? |
| FD1.18 : June to July. | FD2.20 : August. (while looking at the diagram) |
| R : OK ... in what month did the laptop experience the lowest decline? | R : OK ... What is the lowest laptop sales in the month? |
| FD1.19 : February, June, and December | FD2.21 : hmmm.. December and June. |
| R : When is the lowest laptop sales? | R : Are you sure that's all? |
| FD1.20 : August to December. (while looking at the diagram). | FD2.22 : it's February. |
| R : If you sell laptops, what is your sales target each month in one year? | R : In what month laptop sales experienced the lowest decline? |
| FD1.21 : Only 15. If you have a bit of luck, you can add it. | FD2.23 : Same too. February, June, and December. |
| R : Okay .. what can you conclude from the data on students' math tests? | R : Okay .. what can you conclude from the math test data of MTsN Gresik students? |
| FD1.24 : The math test scores of MTsN Gresik students varied, namely 4,5,6,7,9,10 | FD2.26 : In my opinion, the average score of MTsN Gresik students' math tests is around 6 |
| R : Do you agree that most of the students got 7 grades? | R : What grades did the students get the most? |
| FD1.25 : Agree (while looking at the diagram) | FD2.27 : 7 (while looking at the diagram) |
| R : Do you agree that the students only got a minor grade of 5? | R : Do you agree that students only get a score of 5? |
| FD1.26 : Agree (while looking at the diagram) | FD2.28 : Agree (while looking at the diagram) |
FD1 concluded, for problem 1, that sales did not always experience profit. FD1 showed in the diagram in the question that the graph fluctuated (FD1.15 and FD1.21). Laptop sales were the highest from June to July, and the lowest sales were in December (FD1.17, FD1.18, FD. 1.19, and FD1.20). In problem 2, FD 1 concluded that the students' math test scores varied, and the average obtained was 7 (FD1.24 until FD1.26). FD1 was not sure of the answer; this was due to a lack of thoroughness in rearranging the data so that errors occurred. For problem 1, FD2 concluded that the selling price of laptops goes up and down (FD2.18 and FD2.25). Laptop sales were the highest in August, and the lowest sales were in February (FD2.19, FD2.20, FD2.21, FD 2.22, and FD2.23). FD2 stated that the sales target was only five laptops, and for the next month, it was unpredictable. In problem 2, FD2 concluded that the average math test was 6 (FD2.26 until FD2.28). FD2 stated that the value of 7 was the most frequent because it often appeared and the value that appeared less or rarely was 5. FD2 was sure of the answer. Therefore, in this case, FD1 and FD2 gave some appropriate responses when asked to "read the data" and made some global comparisons. FD1 and FD2 also tried to use the data and understood the situation when asked to make conclusions about the data, but the reasons given were not complete. It can be concluded that the statistical thinking of FD1 and FD2 in analyzing and interpreting data is at level 3 (quantitative).
Field- independent students’ stages and level of statistical thinking
Describing data displays (D)
Figure 5 and Figure 6 are the FI students’ answers in describing the data display. This is confirmed by the interview transcript in Table 6.
| FI1 transcript | FI2 transcript |
|---|---|
| R : What information do you get from the diagram? | R : What information do you get from the diagram? |
| FI1.1 : Total sales of laptops in one year, January sold 12 laptops, February 8 laptops, March 18 laptops, April 12 laptops, May 10 laptops, June 8 laptops, July 20 laptops, August 22 laptops, September 18 laptops, October 14 laptops, November 10 laptops, December 8 laptops and the total is 160 laptops in one year. | FI2.1 : The information obtained is about the sale of laptops in 1 year in Barokah Store. January has many sales of 12 pieces, February 8, March 18, April 12, May 10, June 8, July 20, August 22, September 18, October 14, November 10, December 8. |
| R : How can you conclude the same data? Even though January is 12 in the first diagram and 7.5% in the second diagram? | R : Isn't there 23 selling in August? |
| FI1.4 : You can divide 7.5 by 100 times 160 = 12 | FI2.2 : No. (While being shown to diagram) |
| R : Well, what information do you know from number 2? | R : Do the two diagrams show the same data? |
| FI1.6 : Mathematics test scores for class IX MTsN Gresik, with details of the value of 4 obtained by six students, 5 by five students, 6 six students, 7 by ten students, 9 by eight students, and 10 by five students. | FI2.3 : Same. Because I calculated earlier that January was 12, I made 7.5% from (12/160) x 100 |
| R : Isn't August different? | |
| FI2.4 : Same. | |
| R : Okay, what information do you know from question number 2? | |
| FI2.5 : The information obtained is about the grade IX students of MTsN Gresik. The value of 4 was obtained by six students, 5 by five students, 6 by six students, 7 by ten students, 9 by eight students, and 10 by five students. |
Figure 5. The answers of FI1 in describing data display
In Figure 5 and Figure 6, FI1 and FI2 wrote down all the data information on the diagram. FI1 explained that problem 1 was about the number of laptop sales for one year (FI1.1 and FI1.4) and problem 2 was about the value of math tests (FI1.6). Meanwhile, for problem 1, FI2 explained laptop sales in 1 year by writing the number of laptop sales each month (FI2.1 until FI2.4). While problem 2 was about the value of math tests (FI2.5). FI1 and FI2 also stated that the two diagrams use the same data after being proven by calculating the percentages. FI1 and FI2 described the data properly and demonstrated knowledge of chart conditions. They could also recognize when there were two different data presentations on the same data by making appropriate adjustments between the data presented. FI1 and FI2 evaluated two different data presentations on the same data by explaining the relationship between aspects and could be understood. It can be concluded that both FI students’ statistical thinking in describing data display is at level 4 (analytical).
Figure 6. The answers of FI2 in describing data display
Organizing and reducing data (O)
The interview transcript confirms the FI students' answers in organizing and reducing data in Table 7.
| FI1 transcript | FI2 transcript |
|---|---|
| R : What formula do you use to determine the average sold laptop? | R : What formula do you use to determine the average sold laptop? |
| FI1.7 : The total of data values divided by the number of data. | FI2.6 : The total of data values divided by the number of data. |
| R : How do you determine the average? | R : How do you determine the average? |
| FI1.8 : The number of laptops sold is 160 divided by months, namely 12 = 13.3. So, the average laptop sales each month is 13. | FI2.7 : The total number of laptops sold divided the number of months, that is (160/12)=13.33 |
| R : OK .. how do you determine the average of math tests? | R : What formulas did you use to count the average of the math tests? |
| FI1.9 : All the scores are multiplied by the frequency of their scores, then the results are added up divided by the number of students. Obtained 277: 40 = 6.92. | FI2.9 : Same ... average = number of values: the amount of data. |
| R : Is there any other way besides that? | R : How? |
| FI1.10 : Yes, there is like number 1, which is the sum of all the scores and then divided by the number of students. But in my opinion, it's easier to calculate the first way. | FI2.10 : Add up all the scores: the number of students that got (277/40) = 6.92. To make it easier to calculate, all grades are in times the number of students who got that grade. Then the results are added up divided by the number of students. |
In problem 1, FI1 determined the mean (FI1.7 and FI1.8). For problem 2, FI1 added up all the math test scores divided by the number of students to determine the average math score (FI1.9 and FI1.10). For problem 1, FI2 determined the average using the formula of the mean (FI2.6 and FI2.7), resulted in 13,33. For problem 2, FI2 determined the average math score by adding up all the math test scores divided by the number of students (FI2.9 and FI2.10). In this case, FI1 and FI2 group or sort data using several ways and could explain the basis for grouping data. FI1 and FI2 could recognize that data reduction occurred in different ways and provided complete explanations for the different reductions. FI1 and FI2 described “specifically” the data in terms of their mean size. FI1 and FI2 also used the range or size of the data obtained and had the same meaning as the range, which was scale 1. In this case, it can be concluded that the statistical thinking of FI1 and FI2 in organizing and reducing data is at level 4 (analytical).
Representing data (R)
Figure 7 and Figure 8 are the FI students’ answers in representing data. The interview transcript confirms this in Table 8.
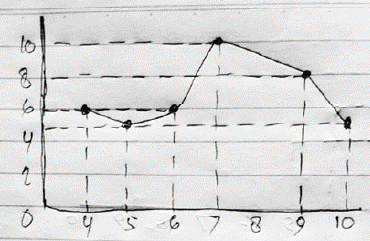
Figure 7. The answers of FI1 in representing data
Figure 8. The answers of FI2 in representing data
| FI1 transcript | FI2 transcript |
|---|---|
| R : What diagrams did you make? | R : What data presentation did you make? |
| FI1.11 : Bar chart. | FI2.11 : Bar chart |
| R : Are you sure about the bar chart? | R : Really? |
| FI1.12 : Hehe… it looks like. | FI2.12 : Hehe yes. |
| R : Where do you know the bar chart from? | R : How do you know the bar chart? |
| FI1.13 : Hehe.. I forgot. (While thinking) | FI2.13 : Hehe, I don't really know. |
| R : What is the shape of the diagram in the question? | R : Is the diagram in the problem the same as the diagram you made? |
| FI1.14 : Hehe… bar diagram too. (While looking and thinking about the diagram in the problem) | FI2.14 : Almost the same (while looking and thinking about the diagram in the problem) |
| R : How do you complete the diagram? | R : How do you complete the diagram in the questions? |
| FI1.15 : Matched with the data | FI2.15 : Connected according to the data that has been presented between math test scores with the number of students. |
In Figure 7, FI1 felt confident in answering problem 2 (FI1.11 to FI1.15). FI1 assumed that the existing diagram was a line chart. In Figure 8, initially, FI2 was sure to answer the problem by making a line graph instead of a bar graph, as asked in the question (FI2.11 to FI2.15). FI1 and FI2 provided good reasons for answering this question, but their graph is not correct. So, FI1 and FI2 were unable to make appropriate data presentations when asked to complete a partially created graph related to a given data set. FI1 and FI2 also worked effectively by using the same scale between the x-axis and the y-axis. FI1 and FI2 produced many precise data representations, some of which rearrange the data. However, FI1 and FI2 draw a line graph instead of a bar graph, as asked in the question. Thus, it can be concluded that the level of statistical thinking of FI1 and FI2 in representing data is transitional.
Analyzing and interpreting data (A)
The interview transcript confirms the FI students' answers in analyzing and interpreting data in Table 9. To answer problem 1, FI1 summarized the overall data in detail. FI1 gave a correct response when asked to determine a laptop sales target every month of the year (FI1.16 and FI1.18). For problem 2, FI1 concluded that the value of math tests at most is 7 and the least is 5 and 10 (FI1.20 and FI1.22). In analyzing and interpreting data of problem 1, FI2 summarized the data that the number of laptop sales in 1 year was 160 laptops (FI2.17 to FI2.18). FI2 gave a proper response when predicting laptop sales targets every month of the year (FI2.19). In answering problem 2, FI2 wrote the number of values from the data that appeared in the math test scores (FI2.20 and FI2.22). So, in this case, FI1 and FI2 made an understandable contextual response to the question, "what information is contained in the presentation of the data." They provided appropriate responses when asked to "read data" and could make relation and understandable comparisons. FI1 and FI2 gave some appropriate responses when asked to make conclusions about the data. Therefore, it can be concluded that the students’ statistical thinking level in analyzing and interpreting data is analytical.
| FI1 transcript | FI2 transcript |
|---|---|
| R : What kind of conclusion do you take on the laptop sales? | R : What can you conclude from the laptop sales data? |
| FI1.16 : From this data, it can be concluded that the number of laptops sold in 2018 was 160 laptops and the average laptop sales per month were 13.3 laptops or 13 laptops. | FI2.16 : The conclusion is that the laptop is sold in 1 year = 160 pieces. |
| R : Okay, what did you conclude from the math test data? | R : Any additional conclusions you want to convey? |
| FI1.20 : From the data, it can be concluded that the most obtained values are 7, and the least are 5 and 10. And the average value is 6.92. | FI2.17 : August was the highest laptop sales, February, June, and December were the lowest laptop sales, the average laptop sales per month were 13.3. |
| R : Perhaps, do you want to state other conclusions? | R : If you are a laptop seller, what is your sales target every month of the year? |
| FI1.21 : Eemmmm ... There are many low math scores in class IX. So, learning should be improved (while looking at the diagram). | FI2.19 : I will target the first month to be between 10-15 laptops. Each month there will be an additional 5 laptops. My target is to increase it every month. The more each month, the better it is. |
| R : How do you know that many math scores are low? | R : Okay, what conclusions did you draw from the math test data? |
| FI1.22 : The high score was 9 and 10 because the km was 7.5. The score 9 belongs to eight students, and 10 is for five students. If you add up, there are only 13 students. Meanwhile, there are 40 students. 40 - 13, right? 27. So there are 27 students whose scores are low. | FI2.20 : The conclusion is that there are 40 students, the total score is 277, the average is 6.92, 7 is the most students score, 5 and 10 are the least students score. |
| R : What is the reason? | |
| FI2.22 : The values 9 and 10 are less than the values 4,5,6 and 7. |
Based on the analysis of FI and FD students’ answers and interviews, a comparison of the students’ stages and levels of statistical thinking is presented in Table 10. Overall, students who have FI characteristics have higher levels of statistical thinking than FD students.
In describing data display, FI students are at the analytical level. In this case, they can mention the information obtained from laptop sales data and data on math test scores entirely and thoroughly. The students confidently stated that the two diagrams were the same data and made reasonable justifications. Meanwhile, FD students were at the quantitative level. They can partially describe the data, are confident in showing their knowledge of the terms of the graph, and recognize when there were two different data presentations on the same data by making partial adjustments to the data in data presentation. Also, they evaluate two different presentations of the same data by focusing on more than one aspect but not explaining the relationship between aspects. This is because FI students tend to be more analytical in seeing a problem; they recalled and retrieved the information from their short- and long-term memory more efficiently than individuals with FD (Mahvelati, 2020).
| Stages of statistical thinking | Levels of statistical thinking | |
|---|---|---|
| FI | FD | |
| Describing data display | Analytical | Quantitative |
| Organizing and reducing data | Analytical | Quantitative |
| Representing data | Transitional | Transitional |
| Analyzing and interpreting data | Analytical | Quantitative |
In organizing and reducing data, FI students were at the analytical level. They were able to classify data using the average formula, use several methods, and explain the basis for grouping them. Whereas FD students were at the quantitative level, the students could do grouping or sorting data and explain the basis for grouping data. They also recognized when data reduction occurs and explained the reasons for the reduction, providing the right size "specifically" that starts approaching one of the centers (mean), although the reasoning is incomplete. Moreover, they could use the obtained measures or the results of the detailed description, but the explanation is not complete. This is because the FI students will use various strategies to formulate or pose a problem from a given situation and a greater capacity to capitalize on an elaborative strategy in the instructional process. On the other hand, the FD students tend to use one method or a well-known previous method (Carrier et al., 1983)
In representing data, FI and FD students were at the transitional level. The students were able to produce data representation, but the answer is not correct. They drew a line graph instead of a bar graph as asked in the test. Moreover, they presented data in the form of line diagrams while what was contained in the problems was a bar chart. They assumed that the diagrams were bar charts. Each student can rearrange and read the data.
In analyzing and interpreting data, FI students were at the analytical level. The students were able to conclude data from diagrams that were presented in whole or in detail. They were also able to read data and make appropriate comparisons and provide appropriate responses when predicting laptop sales targets every month. Meanwhile, FD students were at the quantitative level. These students could conclude data from the diagrams presented, but they did not make a conclusion in detail. They were able to read the data by correctly answering the questions posed by the researcher. However, they were incorrect in making comparisons and were not clear when predicting laptop sales targets every month of the year. This is in line with what Angeli and Valanides (2004) found that FI learners outperformed FD in problem-solving sequentially, clearly, and analytically.
Conclusion
This study found that students with different cognitive styles (FI and FD) reach distinct levels of statistical thinking in four stages of statistical thinking. FD students’ in describing data display, organizing and reducing data, and interpreting data are at the quantitative level, while in representing and analyzing data, they are at the analytical level. On the other hand, FI students are at the analytical level for three stages of statistical thinking and are at the transitional level in interpreting data. Indeed, FI students have higher levels compared to FD students in statistical thinking. The difference is in specific due to their distinct characteristics in problem-solving, which affect their statistical thinking. In fact, FI students are more detailed, systematic in solving statistical problems and use various strategies in solving the problems compared to FD students. Despite this study focusing on only two students in each cognitive style, we argue that the findings provide an insightful lens for understanding students’ statistical thinking based on their cognitive styles in solving mathematical problems. This study also strengthens the results of previous research on the achievement or characteristics of students with FI and FD cognitive styles in problem-solving, where these characteristics also apply to the levels of statistical thinking. Besides that, the findings can be used as starting points for teachers in designing instructions that pay attention to students’ cognitive styles. It is because differences in cognitive style will affect students' performances in mathematics learning. The evaluation of students with different cognitive styles should also be different.
References
- Aizikovitsh-Udi, E., Kuntze, S., & Clarke, D. (2016). Connection between statistical thinking and critical thinking: a case study. In: D. Ben-Zv, & K. Makar (Eds.). The Teaching and Learning of Statistics. Cham: Springer. Doi: 10.1007/978-3-319-23470-0_8
- Akaike, H. (2010). Making statistical thinking more productive. Annals of the Institute of Statistical Mathematics, 62(1), 3–9. Doi: 10.1007/s10463-009-0238-0
- Angeli, C., & Valanides, N. (2004). Examining the effects of text-only and text-and-visual instructional materials on the achievement of field-dependent and field-independent learners during problem-solving with modeling software. Educational Technology Research and Development, 52(4), 23–36. Doi: 10.1007/BF02504715
- Carrier, C., Joseph, M. R., Krey, C. L., & LaCroix, P. (1983). Supplied visuals and imagery instructions in field independent and field dependent children’s recall. Educational Communication & Technology, 31(3), 153–160. Doi: 10.1007/BF02768724
- Cataloglu, E., & Ates, S. (2014). The effects of cognitive styles on naïve impetus theory application degrees of pre-service science teachers. International Journal of Science and Mathematics Education, 12(4), 699–719. Doi: 10.1007/s10763-013-9430-z
- Denzin, N. K., & Lincoln, Y. S. (2005). Introduction: The discipline and practice of qualitative research. In N. K. Denzin, & Y. S. Lincoln (Eds.). Handbook of Qualitative Research, 3rd Edition (pp. 1–32). SAGE Publication, Inc.
- English, L. D., & Watson, J. M. (2015). Exploring variation in measurement as a foundation for statistical thinking in the elementary school. International Journal of STEM Education, 2(1). Doi: 10.1186/s40594-015-0016-x
- Gal, I. (2002). Adults’ statistical literacy: meanings, components, responsibilities.. International Statistical Review, 70(1), 1–25.
- Garfield, J., Le, L., Zieffler, A., & Ben-Zvi, D. (2015). Developing students’ reasoning about samples and sampling variability as a path to expert statistical thinking. Educational Studies in Mathematics, 88(3), 327–342. Doi: 10.1007/s10649-014-9541-7
- Good, T. L., & Brophy, J. E. (1990). Educational psychology: A realistic approach (4th ed.). New York: Longman Publishing Company.
- Groth, R. (2003). High school students’ levels of thinking in regard to statistical study design. Mathematics Education Research Journal, 15(3), 252–268. Doi: 10.1007/BF03217382
- Hudson, T. E., Li, W., & Matin, L. (2006). The field dependence/independence cognitive style does not control the spatial perception of elevation. Perception & Psychophysics, 68(3), 377–392. Doi: 10.3758/BF03193684
- Jones, G. A., Langrall, C. W., Thornton, C. A., Mooney, E. S., Wares, A., Jones, M. R., Perry, B., Putt, I. J., & Nisbet, S. (2001). Using students’ statistical thinking to inform instruction. The Journal of Mathematical Behavior, 20(1), 109–144. Doi: 10.1016/S0732-3123(01)00064-5
- Jones, G. A., Thornton, C. A., Langrall, C. W., Mooney, E. S., Perry, B., Nisbet, S., & Putt, I. (2000). Assessing and fostering children’s statistical thinking. International Association for Statistical Education (ICME) 9, 35–44. http://iase-web.org/documents/papers/icme9/ICME9_06.pdf
- Kilburg, R. R., & Siegel, A. W. (1973). Differential feature analysis in the recognition memory of reflective and impulsive children. Memory & Cognition, 1(4), 413–419. Doi: 10.3758/BF03208900
- Klaczynski, P. A. (1994). Cognitive development in context: An investigation of practical problem solving and developmental tasks. Journal of Youth and Adolescence, 23(2), 141–168. Doi: 10.1007/BF01537443
- Krisdiantoro, S. E., & Prihatnani, E. (2019). Student’s thinking to identify concave plane based on Gregorc model. Beta: Jurnal Tadris Matematika, 12(2), 109–121. Doi: 10.20414/betajtm.v12i2.338
- Kuntze, S., Aizikovitsh-Udi, E., & Clarke, D. (2017). Hybrid task design: connecting learning opportunities related to critical thinking and statistical thinking. ZDM - Mathematics Education, 49(6), 923–935. Doi: 10.1007/s11858-017-0874-4
- Lailiyah, S., Kusaeri, & Rizki, W. Y. (2020). Identifikasi proses berpikir siswa dalam menyelesaikan masalah aljabar dengan menggunakan representasi graf [Identifying students' thinking in solving algebraic problems using graph representations]. Jurnal Riset Pendidikan Matematika, 7(1), 25–44. https://journal.uny.ac.id/index.php/jrpm/article/view/32257
- Lizarelli, F. L., Antony, J., & Toledo, J. C. (2020). Statistical thinking and its impact on operational performance in manufacturing companies: An empirical study. Annals of Operations Research, 295(2), 923–950. Doi: 10.1007/s10479-020-03801-7
- Mahvelati, E. H. (2020). Field-dependent/field-independent learners’ information processing behavior in an implicit learning task: evidence from Iranian EFL learners. Journal of Psycholinguistic Research, 49(6), 955–973. Doi: 10.1007/s10936-020-09712-9
- Marlissa, I., & Widjajanti, D. B. (2015). Pengaruh strategi REACT ditinjau dari gaya kognitif terhadap kemampuan pemecahan masalah, prestasi belajar dan apresiasi siswa terhadap matematika [The effects of REACT strategies based on cognitive styles towards students' problem-solving, learning achievement, and appreciation on mathematics]. Jurnal Riset Pendidikan Matematika, 2(2), 186-196. Doi: 10.21831/jrpm.v2i2.7333
- McIntyre, R. P., & Capen, M. M. (1993). A cognitive style perspective on ethical questions. Journal of Business Ethics, 12(8), 629–634. Doi: 10.1007/BF01845901
- Miles, M. B., & Huberman, A. M. (1994). Qualitative data analysis (2nd edition). SAGE Publication, Inc.
- Mulbar, U., Rahman, A., & Ahmar, A. S. (2017). Analysis of the ability in mathematical problem-solving based on SOLO taxonomy and cognitive style. World Transactions on Engineering and Technology Education, 15(1), 68–73. Doi: 10.26858/wtetev15i1y2017p6873
- Mykytyn, P. P. (1989). Group embedded figures test (GEFT): Individual differences, performance, and learning effects. Educational and Psychological Measurement, 49(4), 951–959. Doi: 10.1177/001316448904900419
- Patton, B. & Santos, E. D. (2012). Analyzing algebraic thinking using “Guess My Number” problems. International Journal of Instruction, 5(1), 5–22.
- Pitta-Pantazi, D., & Christou, C. (2009). Cognitive styles, dynamic geometry and measurement performance. Educational Studies in Mathematics, 70(1), 5–26. Doi: 10.1007/s10649-008-9139-z
- Seo, D., & Taherbhai, H. (2009). Motivational beliefs and cognitive processes in mathematics achievement, analyzed in the context of cultural differences: A Korean elementary school example. Asia Pacific Education Review, 10(2), 193–203. Doi: 10.1007/s12564-009-9017-0
- Sopamena, P., Nusantara, T., Irawan, E. B., Sisworo, & Wahyu, K. (2018). Students’ thinking path in mathematics problem-solving referring to the construction of reflective abstraction. Beta: Jurnal Tadris Matematika, 11(2), 156–166. Doi: 10.20414/betajtm.v11i2.230
- Tinajero, C., & Páramo, M. F. (1998). Field dependence-independence cognitive style and academic achievement: A review of research and theory. European Journal of Psychology of Education, 13(2), 227–251. Doi: 10.1007/BF03173091
- Toomey, N., & Heo, M. (2019). Cognitive ability and cognitive style: finding a connection through resource use behavior. Instructional Science, 47(4), 481–498. Doi: 10.1007/s11251-019-09491-4
- Wild, C. J., & Pfannkuch, M. (1999). Statistical thinking in empirical enquiry. International Statistical Review, 67(3), 223–265. Doi: 10.1111/j.1751-5823.1999.tb00442.x
- Witkin, H. A., Moore, C. A., Goodenough, D., & Cox, P. W. (1977). Field-dependent and field-independent cognitive styles and their educational implications. Review of Educational Research, 47(1), 1–64. Doi: 10.3102/00346543047001001
